引言
SAM 系列模型引入了图像和视频的提示分割任务,专注于使用点、框或掩码进行提示式视觉分割(Prompt Vision Segmentation,PVS),以每个提示分割单个物体。虽然这些方法取得了突破性进展,但它们并未解决在输入中查找和分割任何出现位置的概念的所有实例的通用任务(例如,视频中所有的“猫”)。
为弥补该研究空白,Meta 推出 SAM3 模型。相较于 SAM2,SAM3 对 PVS 模块进行优化升级,同时为 可提示概念分割(PCS) 任务建立了全新标准。
- 为了专注于识别原子视觉概念,Meta 将文本限制为简单的名词短语,例如“红苹果”或“条纹猫”。
SAM 3 (Segment Anything Model 3)是 Meta 推出的第三代“分割一切”模型。在 SAM 2 的基础上,SAM 3 的核心突破在于引入了基于概念的提示分割能力。它不再局限于通过点、框等几何提示来分割单个物体,而是能够根据用户提供的概念提示(如名词短语“黄色校车”、图像示例或两者结合),在图像和视频中检测、分割并跟踪所有匹配该概念的物体实例。
注:本文仅关注 SAM3 的图像语义分割部分。
可提示概念分割(PCS)
定义 Promptable 概念分割任务如下:给定一个图像或短视频(≤30秒),检测、分割和跟踪由简短文本短语、图像示例或两者的组合所指定的视觉概念的所有实例。
- 将概念限制为由简单名词短语(NPs)定义的,名词短语由一个名词和可选的修饰符组成。
- 名词短语提示(如果提供)对图像/视频的所有帧都是全局的,而图像示例可以作为正或负边界框在单个帧上提供,以迭代地细化目标掩码。
SAM3 模型架构
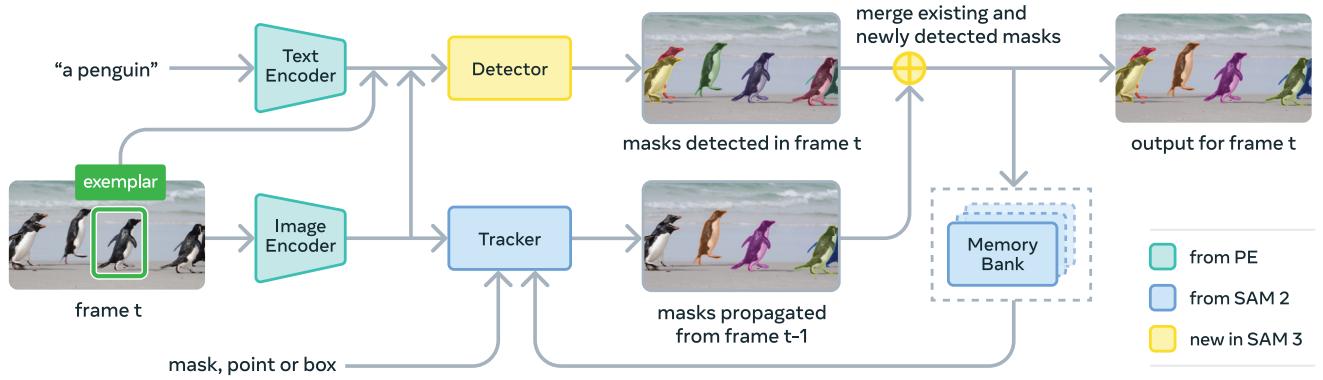
SAM3 架构基于 SAM 系列和 DETR 架构,是一个双编码器-解码器 Transformer 系统。它主要由两部分组成:检测器与跟踪器,二者共用同一视觉编码器。
核心组件如下:
- 感知编码器(Perception Encoder, PE)
- 基于 DETR 的 检测器:从文本或视觉提示词中定位目标。
- 基于记忆的 跟踪器:将检测结果传播到各视频帧。
- 存在性头(Presence Head):SAM 3 的关键创新之一,将“物体是否存在”的全局判断与“物体在哪里”的局部定位解耦,显著提升检测准确率。
SAM3 有 ~850M 个参数,~450M 和 ~300M 用于视觉和文本编码器,以及 ~100M 用于检测器和跟踪器组件。
图像实现细节
检测器在推理时产生一个包含以下主要键的字典:
| 输出键 | 形状 | 描述 |
|---|---|---|
| pred_logits | (batch, num_queries, 1) |
每个查询的检测置信度 |
| pred_boxes | (batch, num_queries, 4) |
归一化的 (cx, cy, w, h) 框 |
| pred_boxes_xyxy | (batch, num_queries, 4) |
转换后的 (x1, y1, x2, y2) 框 |
| pred_masks | (batch, num_queries, H, W) |
二进制分割掩码 |
| presence_logit_dec | (num_layers, batch, 1) |
每层存在性分数 |
| queries | (batch, num_queries, d_model) |
最终解码器隐藏状态 |
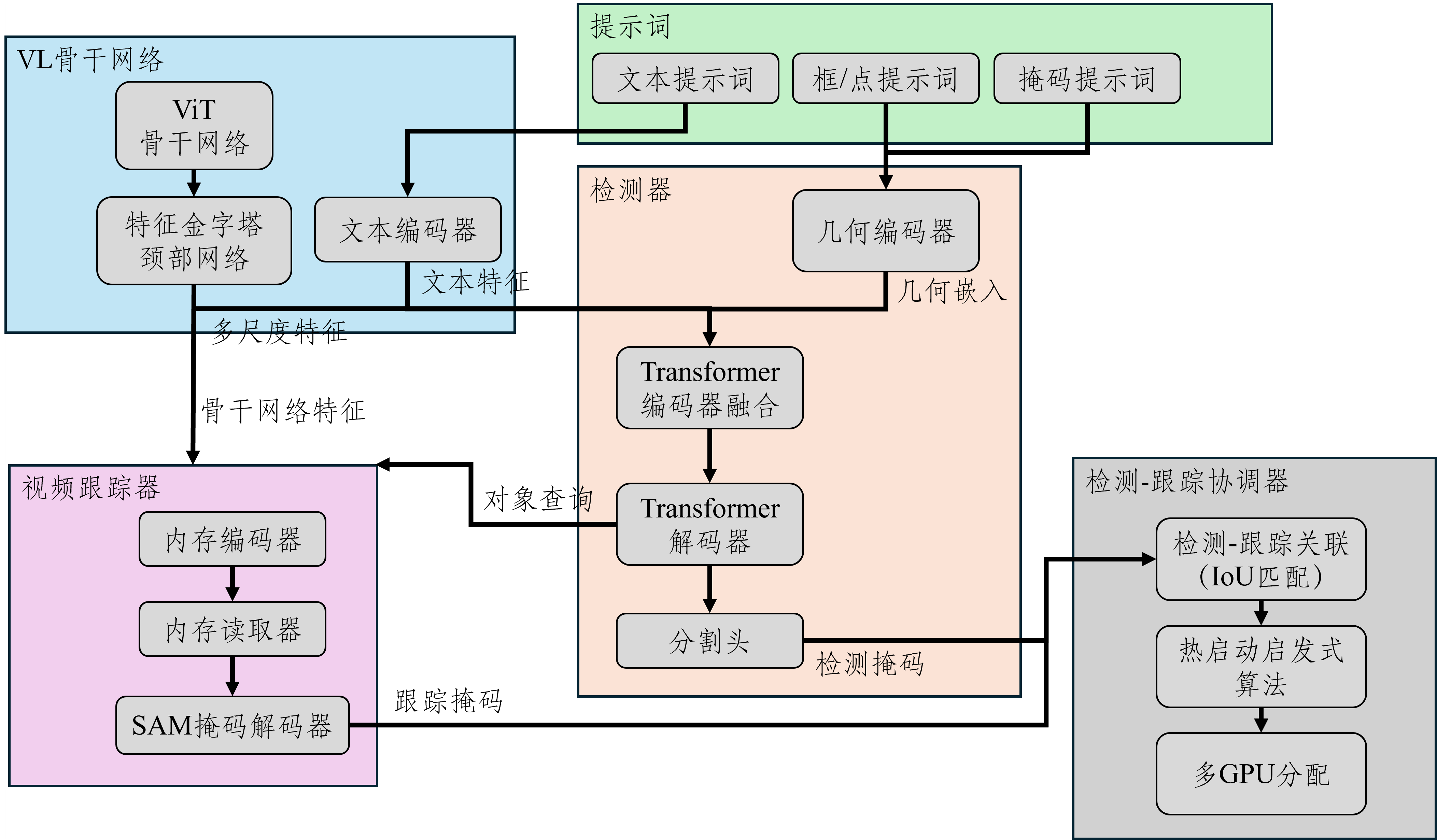
Image and Text Encoders
图像和文本编码器是 Transformer 模型,使用 5.4 亿个图像‑文本对,遵循感知编码器(Perception Encoder, PE)进行对比视觉语言训练。
- 与 SAM2 类似,视觉编码器使用窗口注意力,并在极少数层(32层中的4层)使用全局注意力,其中 1008×1008 像素的图像被划分为 3×3 个非重叠的 336 像素窗口。
- 视觉编码器每层都使用 RoPE,并使用窗口化绝对位置嵌入。
- 文本编码器最大上下文长度为 32。
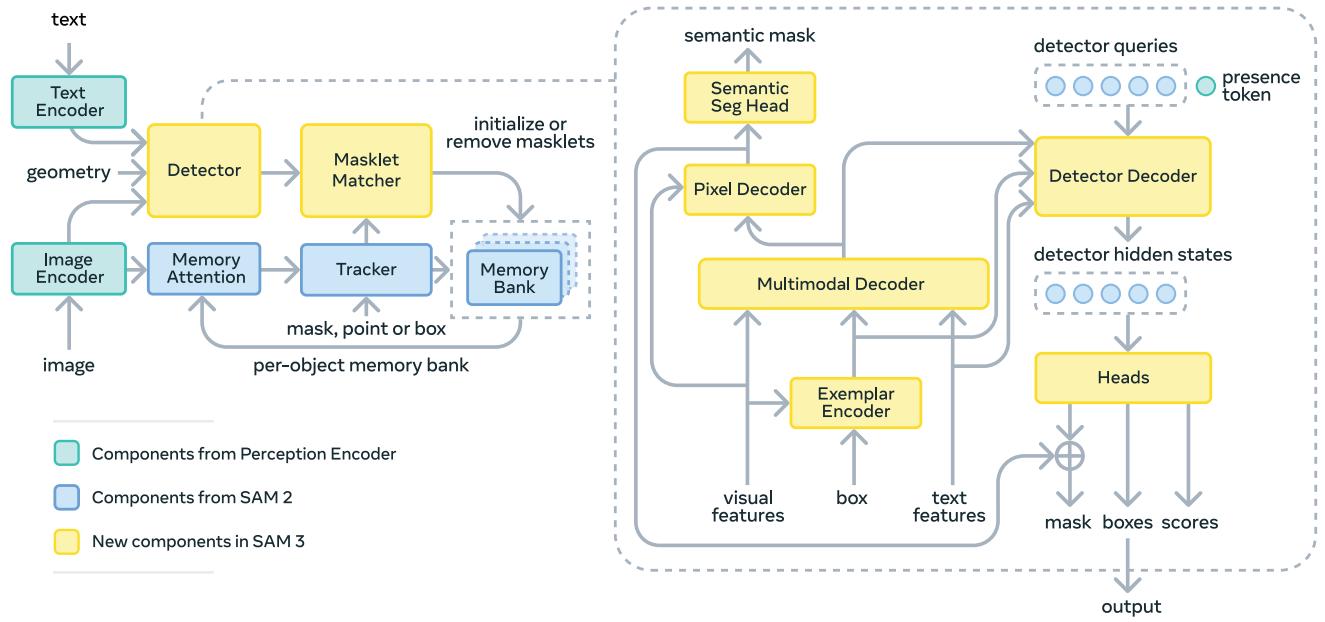
Geometry and Exemplar Encoder
几何与示例编码器主要用于对 PCS 任务中的图像示例(如果存在)进行编码。
- 此外,它还作为辅助功能用于对图像上的 PVS 任务进行视觉提示编码,该功能主要用于在训练的 2‑3 阶段将 PVS 任务的预训练数据包含在内,以实现更模块化的训练方法。
每个独立的图像示例都使用位置嵌入、标签嵌入(正向或负向)以及 ROI 池化的视觉特征进行编码,这些特征被连接(组成“Exemplar tokens”)并由一个小型 Transformer 处理。辅助训练的视觉提示(点、框)以类似方式编码,组成“Geometry tokens”。
- 可能存在“Geometry tokens”和“Exemplar tokens”均不存在的情况(例如仅使用文本提示时)。
- Geometry tokens 和 Exemplar tokens 通过自注意力机制相互关注,同时也交叉关注图像编码器对应(无条件)帧的 frame-embedding。
融合编码器
文本和几何/示例标记共同构成 prompt tokens(提示标记)。融合编码器接受未条件化的 frame-embedding,并使用一个包含 6 个 transformer 块的堆栈对 prompt tokens 进行条件处理,随后搭配多层感知机(MLP)完成特征映射,输出条件化的 frame-embedding。
- transformer 块带有自注意力和交叉注意力(针对 prompt tokens)层,且自注意力层是普通的自注意力操作。
解码器
SAM3 系统采用两个独立的解码器栈,根据推理任务的不同进行调用。
- DETR 风格解码器负责“理解场景”(检测 + 语义 + 实例),接受文本、框、或文本 + 框组合,输出是“场景中有哪些物体、在哪里、掩码是什么”,面向开放世界理解。
- SAM 风格掩码解码器负责“精细抠图”(交互式分割),接受点、框、掩码提示,输出是“根据用户指出的位置,精细抠出这个物体”,面向交互式修正。
DETR 风格解码器也是一个包含 6 个 transformer 块的堆栈。Q 学习的对象查询(Object Queries)在内部进行自注意力交互,并与提示标记以及条件帧嵌入进行交叉注意力交互,随后经过一个 MLP 进行预测检测框和分数。在关注条件帧嵌入的交叉注意力层中,使用了框到像素的相对位置偏差。
- DETR 风格解码器的
d_model为 256,即每个查询的隐藏维度为 256。
Segmentation Head
语义分割和实例分割共享同一个分割头。
融合编码器产生的条件特征用于生成语义分割掩码,而实例分割额外使用解码器的输出 Object Queries。
视觉编码器是一个单尺度 ViT,所以多尺度特征通过 SimpleFPN 提供给分割头。
- SimpleFPN 产生多尺度列表 → Encoder 编码 → PixelDecoder 做经典的 FPN 自顶向下融合 → 生成统一分辨率的像素嵌入供 mask 预测
Presence Head & Presence Token
存在标记:一个学习到的全局标记,用于预测目标概念是否存在于图像/帧中,通过将识别与定位分离来改进检测。
- 通过引入一个学习得到的全局存在标记来将识别和定位步骤解耦。这个标记仅负责预测符合名词短语(NP)概念的目标是否存在于图像/帧中。每个查询 只需要解决定位问题。每个查询的最终得分是其自身得分与存在得分的乘积。
跟踪器架构
不关注视频处理,略
SAM3 代码仓库
代码仓库地址:https://github.com/facebookresearch/sam3
1 | sam3/ |