关键词:深度学习、模型、多模态、目标检测
引言
开放世界目标检测旨在 定位和识别固定封闭集标签空间之外 的物体。
它通常分为两类,即:
- Open-Vocabulary(开放词汇检测):在测试时提供预定义的类别列表。
- Open-Ended(开放式检测):在推理过程中自动生成候选类别。
当前的检测方法主要依赖文本语义和模型内部的参数化知识。语言可以指定“检测什么”,但无法提供“目标在图像中具体长什么样”的细粒度视觉线索。这种局限性在处理长尾类别(罕见类别)、类内外观差异大以及杂乱场景时尤为明显。
- 例如,文本“狗”压缩了品种、姿态、视角等巨大变化,导致检测器难以准确定位。
论文提出了 VL-SAM-v3 框架,主要贡献包括:
- 提出首个同时支持开放词汇和开放设定检测的框架,通过外部视觉记忆增强检测器提示。
- 检索与优化机制:引入非参数化记忆库,将检索到的视觉证据转换为稀疏和密集先验,并通过“记忆引导的提示优化”模块与原始提示融合。
- 卓越性能:在 LVIS 数据集上的零样本实验中,开放词汇和开放式检测性能均获得持续提升,特别是在罕见类别上取得了显著增益。
模型流程
模型整体分成两大阶段:
text1
2
3
4
5
6
7
8
9
| ┌────────────────────────────────────────────────────────┐
│ 阶段一:建场景感知视觉记忆库(离线,训练前一次性完成) │
└────────────────────────────────────────────────────────┘
↓
┌────────────────────────────────────────────┐
│ 阶段二:在线推理 │
│ │
│ 检索 → 生成先验 → 记忆引导提示优化 → 解码 │
└────────────────────────────────────────────┘
|
在线推理阶段:
text1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| 输入图像 + 候选类别 "狗"
│
▼
┌──────────────────┐
│ ① 类别条件检索 │ 去记忆库查"狗"的视觉原型
│ 得到原型 p_c │
└────────┬─────────┘
│
▼
┌────────────────────────┐
│ ② 生成视觉先验 │
│ 密集先验 H_c(热力图)│ 像"荧光标记"涂在图上
│ 稀疏先验 A_c(锚点) │ 像"图钉"钉在热点上
└────────┬───────────────┘
│
▼
┌────────────────────────┐
│ ③ 记忆引导提示优化 │
│ 稀疏特征 + 密集特征 │ 从记忆库提取的两种线索
│ + 检测器原始提示 │ 三者融合成精炼提示 z_j
└────────┬───────────────┘
│
▼
┌──────────────────┐
│ ④ 标签约束解码 │ 每个提示只投自己的类别
│ → 最终检测结果 │ 防止跨类别干扰
└──────────────────┘
|
模型架构
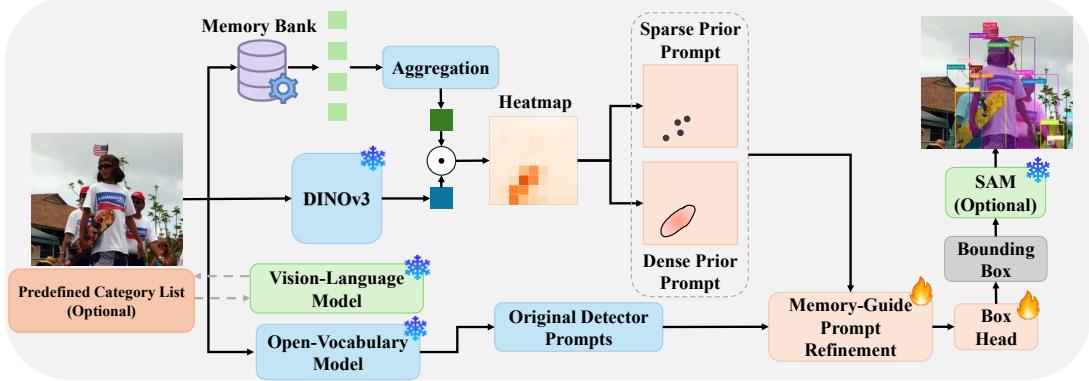
VL‑SAM‑v3 的整体流程如图 1 和图 2 所示,核心思路是:构建一个外部视觉记忆库,在推理时检索与候选类别最相关的视觉原型,转化为稀疏和密集两种先验提示,再通过记忆引导的提示精炼模块,与原始检测器提示融合。
问题设置
给定图像 I,目标是定位并识别来自候选类别集 C 的对象。在开放词汇检测中, C 在测试时提供,在开放式推理中则生成。VL‑SAM‑v3 在两种设置中使用相同的流程,仅在如何获得 C 上有所不同。
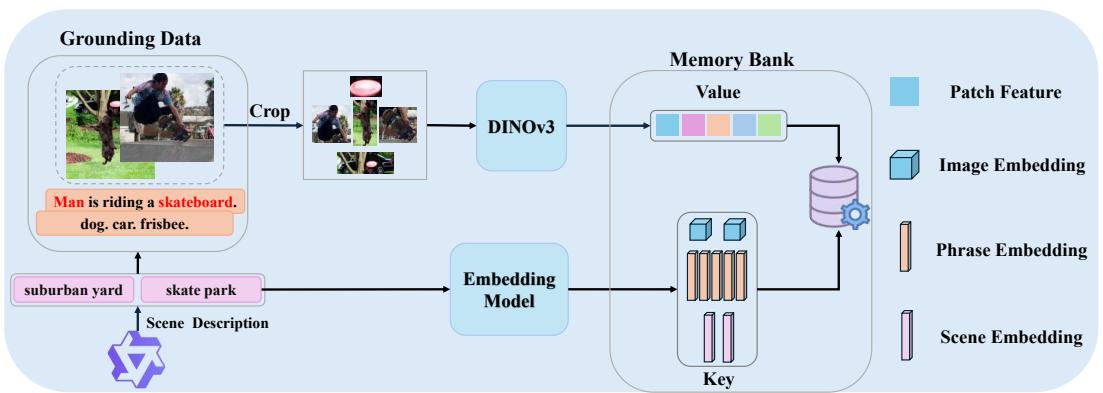
场景感知视觉记忆
从 grounding-style 数据构建场景感知视觉记忆,其中每个条目存储一个检索 Key ki 和一个区域级视觉 Value vi。
| 组成部分 |
符号 |
含义 |
计算方式 |
| 检索 Key |
ki |
用于相似度检索的向量 |
融合词语文本、场景描述文本、图像全局视觉三种信息 |
| 视觉 Value |
vi |
保留区域外观特征 |
在边界框内对 DINOv3 patch 特征做均值池化 |
给定图像 I 、真实边界框 bi 以及对应的类别或词语 ti,首先使用 VLM 描述 I 的场景 s,ki 和 vi 的计算公式为:
ki=vi=Norm(wpEtext(ti)+wsEtext(s)+wgEimg(I))Norm(Pool(F(I),bi))(1)
- wp、ws、wg 分别表示词语内容、场景上下文和图像级视觉上下文的权重。
- Etext、Eimg 分别表示多模态嵌入模型的文本编码器和图像编码器。
- F(⋅) 表示 DINOv3 特征编码器;Norm(⋅) 是 l2 归一化。
- Pool(F,bi) 表示在框 bi 内的 DINOv3 patch 特征上进行的均值池化。
在该方程 (1) 中,ki 用于优化场景感知检索,而 vi 则保留了 DINOv3 特征空间中真实区域的外观。
这种设计使得检索不仅是简单的"类别名匹配",而是融合了场景感知能力。
- 比如"狗"在"公园"场景和"客厅"场景下,检索到的视觉原型会有所不同。
类别条件检索
对于每个候选类别 c∈C,在记忆键 ki 相同的空间中形成一个结合类别文本以及当前图像场景和全局视觉上下文的查询 qc:
qc=Norm(wpEtext(c)+wsEtext(s)+wgEimg(I))
然后计算 qc 与视觉 Memory 中每个 ki 之间的相似度,并选择前 K 个检索到的条目及其索引 Nc。最后检索到的值被聚合(加权平均)为特定类别的视觉原型 pc 作为输出:
pc=Norm(i∈Nc∑αivi)
其中 αi 计算如下:
αi=∑m∈Ncexp(<qc,km>/τp)exp(<qc,ki>/τp)
原型 pc 总结了在 DINOv3 特征空间中检索到的关于类别 c 的证据。
类比:你要在"公园照片"里找狗,就去图书馆查"公园场景下的狗"的索引,翻出最像的几张参考图,合成一张"狗的标准照"。
基于检索的视觉先验
将视觉原型 pc 投影到输入图像 Iinput 上,生成两种互补的视觉先验:
- 用于类别感知空间支持的密集先验;
- 用于实例级锚点的稀疏先验。
类比:密集先验 = 在照片上涂一层"狗可能在这里"的荧光标记;稀疏先验 = 在荧光最亮的地方钉上图钉。
密集先验
计算 Iinput 每个 patch 与 视觉原型 pc 的相似度,得到类别特定的 heatmap 热力图:
Hc=MinMax(Smooth(<Norm(F(Iinput)),pc>))
- Smooth(⋅) 表示空间平滑;
- MinMax(⋅) 将热力图缩放到 [0,1] 范围。
Hc 衡量输入图像特征与检索到的原型 pc 之间的兼容性,其响应高的区域(热区)即为类别 c 的候选区域。
稀疏先验
由于 Hc 提供密集支持但不是显式的实例中心,所以从热力图中找出局部最大值,提取稀疏锚点。
- 具体来说,按响应对候选峰值进行排序,并使用基于距离抑制重复点,得到候选实例中心 Ac=aj 。
Hc 和 Ac 组成检索引导的视觉先验。
基于记忆的提示优化
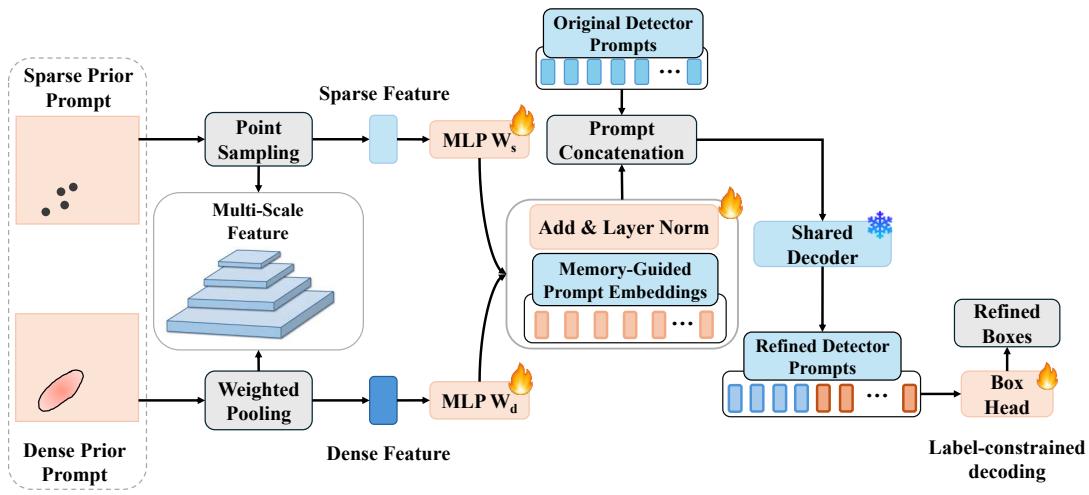
给定密集先验 Hc 和稀疏锚点 Ac,为类别 c 构建了记忆引导的提示嵌入,如图 3 所示。
具体来说,对于原始检测器的多尺度特征,在每个尺度上独立进行以下细化。令 M 和 e 分别表示检测器的特征和原始可学习的提示先验。首先从检测器的特征中为每个锚点 αj∈Ac 提取稀疏特征。
fjs=Sample(M,αj)
其中 Sample(⋅) 表示在锚点位置进行双线性特征采样。
之后,为了从 Ac 中提取密集特征,在每个锚点 αj 处构建局部窗口 Ωj
,在 Ωj 内,使用 Hc 作为权重,从 M 计算密集特征,公式如下:
fjd=(x,y)∈Ωj∑Hc(x,y)M(x,y)
最后,将稀疏特征 fjs 和密集特征 fjd 和检测器的原始提示先验 e 融合为:
zj=LN(e+Wsfjs+Wdfjd)
- 原始可学习提示保持了原有检测能力,稀疏特征提供实例级线索,密集特征提供局部上下文线索。
原本检测器只有一个模糊的"狗"的概念(e),现在额外给了它两张参考图——一张是精确的实例特写(稀疏),一张是周围环境的整体印象(密集)。三张图叠在一起看,判断自然更准。
Ws 和 Wd 是可学习的投影,LN(⋅) 是层归一化。每个精炼的提示结合了检测器的原始查询和两个由记忆导出的线索,即稀疏实例级线索和一个密集局部上下文线索。
标签约束解码
在所有编码器层完成精炼后,收集生成的记忆提示 {zj}。
每个记忆引导提示 zj 与其在前面的类别 tj 相关联。为了防止跨类别漂移,允许记忆引导提示只为它的源类别投票。令 sj(c) 表示提示 zj 对于输入候选类别 c∈C 的分类逻辑值。通过以下方式强行执行约束:
sj(c)={sj(c),−∞,c=tjc=tj
也就是说,提示 zj 仅对类别 tj 有贡献,而检测器的原始提示在全局开放世界搜索中保持不变约束。
类比:狗的资料只能用来找狗,不能拿去认猫。防止记忆提示"越权干扰"。
在训练过程中,通过使用真实边界框中心作为锚点近似,并使用相同的内存机制离线预计算特定类别的密集先验,从而避免了在线检索。然后,使用与基础检测器相同的监督来优化检测器。在推理过程中,针对每个候选类别执行在线检索,以构建 pc、 Hc、 Ac 以及相应的内存引导提示。
References
- VL-SAM-v3: Memory-Guided Visual Priors for Open-World Object Detection
Learn together with DeepSeek-V4-pro